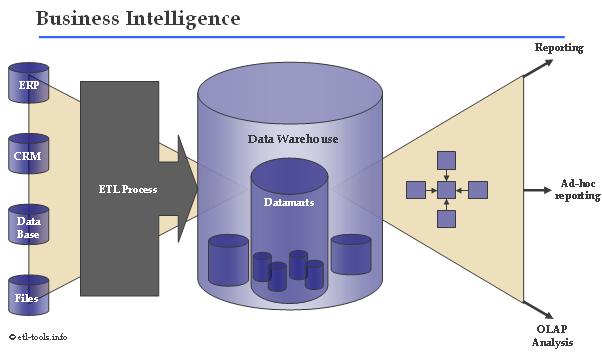
Below is an image to describe the difference visually:

Another key difference that this article mentions is that OLTP has a more normalized database structure, whereas OLAP will have less normalized relations. This brings us to dimensional modeling with various types of schema.
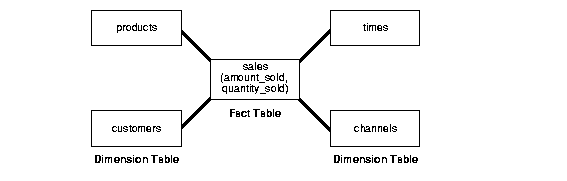
Star Schema requires fact tables and dimension tables. A dimension can categorize data so that users can interact with the data warehouse in different ways. Dimensions are typically small with not too many rows. A fact table is created by having measures or numberic facts that want to be analyzed, and multiple foreign keys to connect to the various dimensions. Fact tables will continue growing and can be very large, which will make processing time longer.
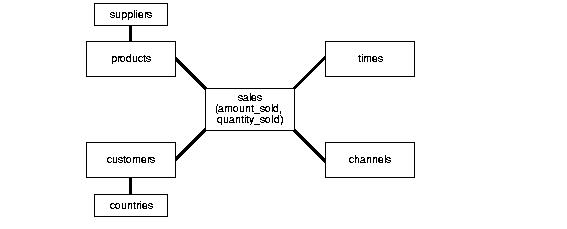
Snowflake schema is a more complex version of a Star schema where the dimensions are more normalized. Fact tables connect to the dimensions similarly to star schema, but then they can also connect to dimensions through dimensions, which can be defined through various relationships.
Data warehouses can use a hybrid approach of star and snowflake schema if they want to normalize only certain dimensions. This can be beneficial so that the structure is not too complex, but allows the user to do the necessary analysis.
As illustrated, dimensional modeling is an important part of data warehousing and the schema defines the structure. Analysis is much better with a correct data warehouse instead of using the database structures to perform similar analysis. I have been using SQL Server 2005/2008 to develop data warehouses and specific cubes. I am currently looking into SQL 2012 to see the additional features and functionality that it offers.